



DeepSeek 引發的熱議:如何改變全球AI競爭格局?


最近無論是在工作還是在休閒的時候,都被 DeepSeek 這家公司給刷屏了。到處都能看到相關的報導,而且也就在過去的一週時間,它對於美國科技股的衝擊也是巨大的 —— 至少說短期來看是這樣的。
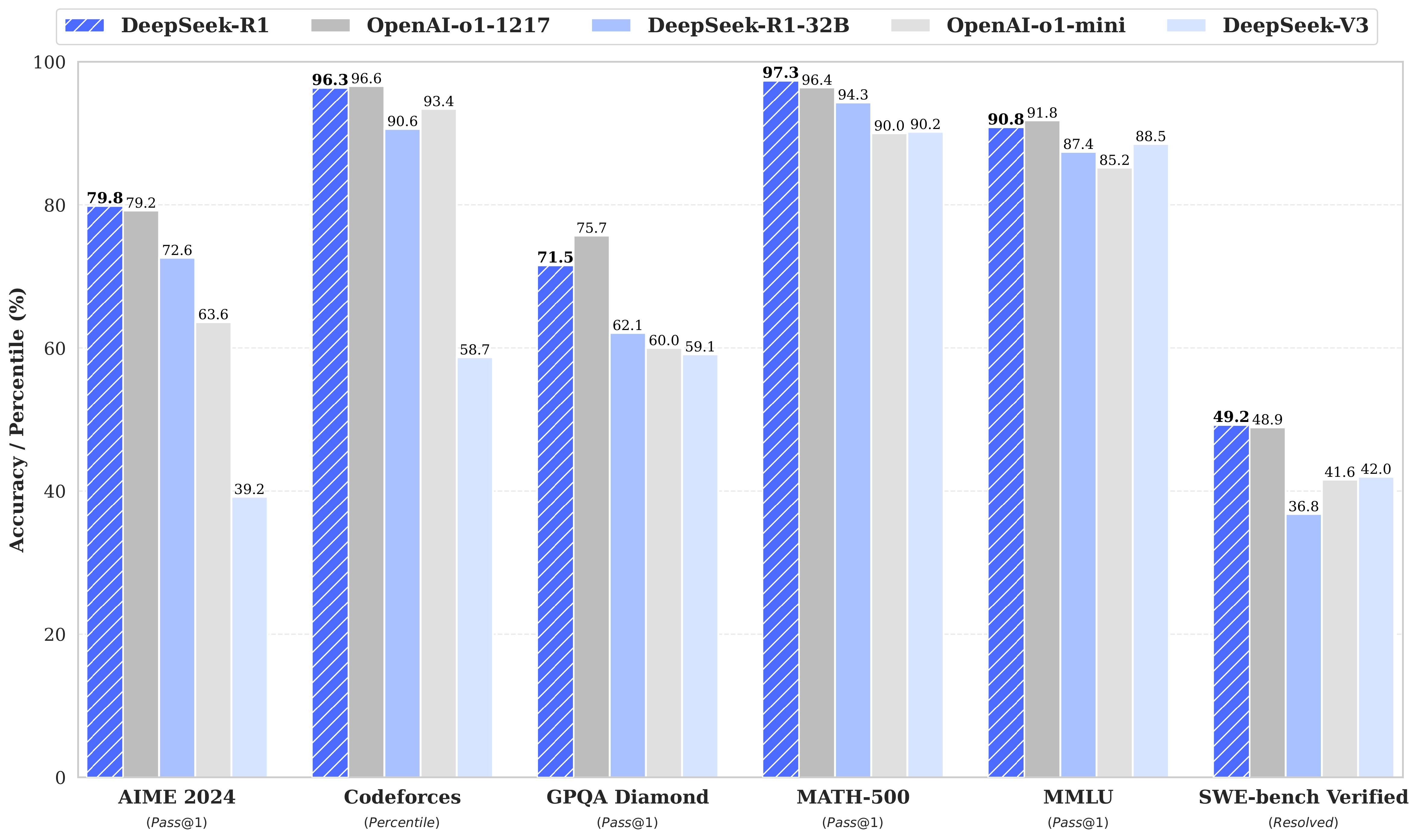
DeepSeek,一家成立於2023年的中國人工智能公司,以其低成本、高性能的模型震驚全球。其最新模型DeepSeek-V3的訓練成本僅為557.6萬美元,遠低於OpenAI GPT-4o模型高達1億美元的訓練成本,這一數據引發了業界對其技術創新的廣泛討論[2][5][10]。
然而,這些突破背後也帶來了許多值得探討的問題:
DeepSeek R1 和 V3 模型背後的技術成就是如何改變AI行業規則?
它的影響是否僅限於技術層面,還是會對全球科技競爭格局產生深遠影響?
為了思考這兩個問題,我會思考這樣的幾個角度:
DeepSeek 在技術方面的創新和成就;
為什麼 DeepSeek 模型的成績會對於AI行業具有衝擊力;
中美科技競爭中的挑戰與矛盾。
DeepSeek的技術成就
高效算法與技術突破
DeepSeek-V3採用了混合專家(MoE)架構和多令牌預測(MTP)技術,實現了極高的計算效率。雖然 MoE 理論並非全新的架構 —— 這一套理論最先發表於 1991 年,然而 DeepSeek 所開發出來的整個模型擁有6710億參數,但僅使用2048塊GPU進行了2個月的訓練,總計消耗280萬GPU小時[5][8]。這依舊是讓人震驚不已的成績。
相較於OpenAI等公司依賴大量算力堆砌的方法,DeepSeek通過數據壓縮和選擇性處理來優化算力使用。這種方法不僅降低了成本,還提升了模型性能,使其能夠在有限資源下與頂尖模型競爭[6][8]。
當然,現在對於宣布的成本,還有許多需要詳細觀察和考證的地方。也有不少硅谷的大佬對於這些數值產生了質疑。其中DeepSeek被指控通過“蒸餾”方法使用OpenAI數據進行訓練,引發數據倫理爭議。儘管其聲稱技術完全獨立,但外界仍存疑慮[3][7]。
關於在 AI 模型訓練中的“蒸餾”技術,有興趣的可以看看這兩篇:


開源模式的影響
DeepSeek選擇MIT許可證開源,這一舉措讓更多中小型企業和研究者能夠以更低成本使用先進技術。API定價也極具競爭力,每百萬輸入tokens僅需1元(緩存命中)或4元(緩存未命中),大約是OpenAI同類產品運行成本的三十分之一[5]。
開源策略不僅推動了技術普及,也挑戰了現有商業模式,尤其是封閉式開發模式下的大型科技公司。
對AI行業的衝擊
市場影響
DeepSeek的低成本模型直接衝擊了科技股市場。例如,美國芯片巨頭Nvidia因為市場對算力需求下降的預期而股價受挫[1]。
此外,其開源策略可能削弱大型科技公司的壟斷地位,但也引發了對數據安全和濫用風險的擔憂。
技術生態變革
開源模式加速了AI技術普及,但也帶來競爭加劇和利潤壓縮挑戰。例如,Meta已成立專門研究小組以改進其Llama模型,希望追趕DeepSeek在成本效率上的突破[5]。
在模型訓練的過程,一般我們都會理解為有三個最主要的基礎元素,它會直接影響所得到模型的優劣程度:算力,算法,和數據。DeepSeek 之所以能夠在 AI 圈內造成如此大的轟動,也正是挑戰了這三個原則。
Nvidia 作為現在 AI 圈內的龍頭,正是站在了算力這一元素上。以前,我們認為,想要得到一個優秀的模型,那麼就必須投入相對應的算力與大量的數據。
DeepSeek 卻似乎打開了另一個可能性 —— 通過數據蒸餾與適當的 MTP 架構,我們可以通過一個優秀的大語言模型,在有限的算力下,產生非常強大的AI模型。這樣的思路,便實實在在地挑戰了投資Nvidia 的底層邏輯。
然而,如果簡單地得出 Nvidia 已死這個結論,也顯得過於草率。儘管我們證明了對於“學生模型”對於算力的降低,然而這也極度仰仗於有一個優秀的“教師模型”。對於教師模型的研究和訓練,Nvidia 的算力技術依舊是無法撼動的。
同時,一個叫做 Jevon's Paradox (杰文斯悖論)也值得一提。簡單地來說就是 —— “当某种资源的使用效率提高时,人们往往会增加对该资源的需求,导致总消耗量反而上升,而不是下降。” 此刻這裡的資源便是 Nvidia 所提供的AI 算力,換句話說,我們在未來將更加渴求算力。
全球視角:中美科技競爭與倫理挑戰
如果單單看技術層面,我想對於DeepSeek 事件來說,還不夠完善。
DeepSeek的崛起不僅是技術事件,更是一個地緣政治事件。其低成本高效能模型被視為中國對抗美國科技封鎖的一次成功嘗試:
美國大模型巨頭如OpenAI和Anthropic認為DeepSeek並未超越其技術,但也承認其在成本效率上的優勢具有重要意義[1][6]。
同時,多國政府對DeepSeek可能帶來的信息安全風險表示擔憂。例如,美國部分企業已限制使用其產品,而Meta等公司則積極研究其技術以應對競爭[5][6]。
此外,DeepSeek在言論審查上的表現也引發爭議。其模型在中國市場遵守本地法律進行內容過濾,但這種行為在國際市場上被視為價值觀輸出的工具,引發信任危機。
似乎在如今的地緣政治格局之下,AI 這片土地,也勢必成為中美對抗裡的一枚重要棋子。
未來展望

對研究者與消費者的影響
更低成本、更高效能是否能推動AI普及化?例如,DeepSeek API的低價格可能使更多中小企業得以使用先進語言模型[5]。
現在 AWS 上已經可以部署 DeepSeek 的模型了。因為低算力的要求,這可以進一步的降低企業成本。在許多的商業案例中,我一直看到的並非是需要像一個 GPT-4o 這樣強大的模型,反而是需要小而細緻的模型。AI應用場景將更加多元化,但也需考慮如何平衡創新與安全。
試想一下,如果我們不斷減低本地部署AI 模型的需求,那麼我們將在未來許設備上可以擁有本地 AI,而非如今需要通過聯網的 Cloud AI。這樣對於個資安全,應用環境,都將是非常大的拓展。
個人結論
DeepSeek 的技術成就和開源策略我認為是巨大地衝擊了現在的AI行業規則,也為中美科技競爭注入了新的變量。然而,其成功背後隱藏著諸多矛盾與挑戰,例如數據倫理問題、技術濫用風險以及價值觀衝突。
References:
[1] DeepSeek惊艳全球,美国大模型两巨头齐发声:并不比我们先进 https://wallstreetcn.com/articles/3740216
[2] 专访:DeepSeek为何能在AI大模型中脱颖而出 https://www.dw.com/zh/专访deepseek为何能在ai大模型中脱颖而出/a-71481279
[3] DeepSeek利空算力? https://wallstreetcn.com/articles/3740060
[4] 【人工智能】DeepSeek到底花了多少钱| SemiAnalysis深度报道| 幻 ...
[5] DeepSeek震惊世界:团队没有“海归”,训练成本不到GPT的1/20 https://finance.sina.com.cn/roll/2025-01-27/doc-inehkyez8803444.shtml
[6] DeepSeek为何在美国引起巨大关注? https://news.cctv.com/2025/01/28/ARTI0MXQfQvjItIHa5ZX9Wj1250128.shtml
[7] 马斯克质疑DeepSeek的r1模型训练成本分析数据造假,你怎么看? https://www.zhihu.com/question/10789936603
[8] Deepseek V3模型解读:算力不再关键了吗? - 韭研公社 https://www.jiuyangongshe.com/a/6gweksbze7
[9] DeepSeek惊艳全球,美国大模型两巨头齐发声:并不比我们先进 https://www.yeeyi.com/news/details/2600882/
[10] DeepSeek被称为AI界拼多多 训练2个月花557.6万美元 https://www.yeeyi.com/news/details/2598998/